前言
信息的来源与形态具有多样性,每种形态的数据都称为一种模态。就像人可以通过听觉、视觉、触觉来感知语音、图像、文本等多模态信息。深度学习针对这几种模态的信息产生了几个分支:自然语言处理、计算机视觉、语音识别等,采用不同特点的模型处理不同模态的信息。
多模态机器学习旨在让机器能够处理和理解多模态信息的能力,也就是同时利用文本、图像、语音等信息以及它们之间的交互,而不是只利用一种信息去做下游任务。只要能够转换成数字形式并且保留语义信息的数据,都能被机器加以利用。
1 介绍
本文介绍一种基于多模态数据的情感分析模型——VistaNet
论文:VistaNet: Visual Aspect Attention Network for Multimodal Sentiment Analysis
该模型针对 Yelp.com 上的评论数据进行五级评分预测,即五分类任务。每条评论数据包含数量不一的图片,以及多个句子的文本。
VistaNet 利用 Attention 机制进行图像与文本信息的融合,巧妙的解决了不同模态数据的向量空间不一致问题,增强了模型针对评论的情感分析的能力。
模型结构图如下:
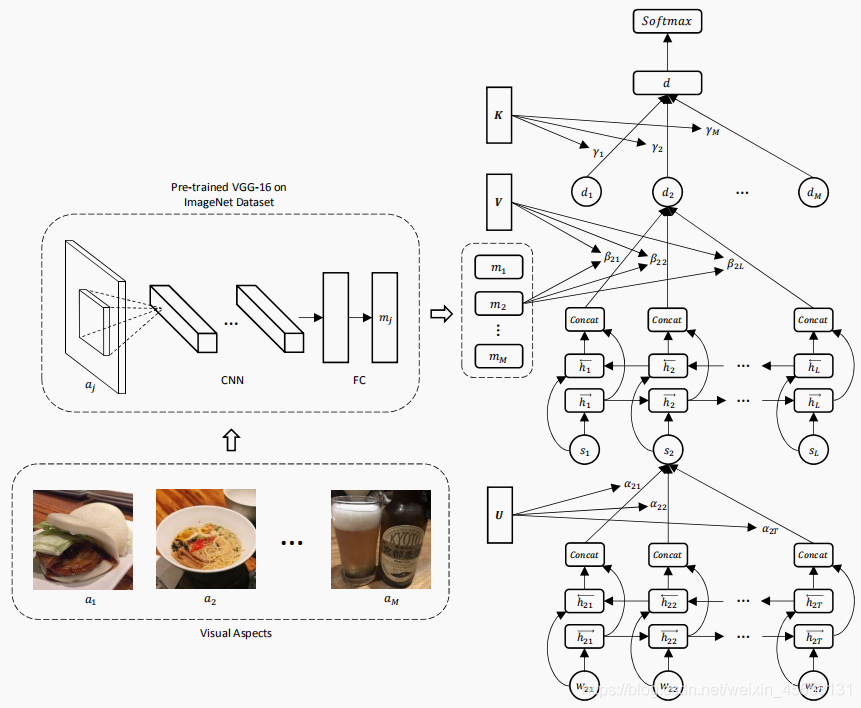
2 原理
模型从下往上可分为三层:
- Word Encoder + Attention
该层用于对每段评论文本中的各个句子 si 进行嵌入,输入数据为每个句子的各个单词的词向量 w (最大单词个数为T,词向量是使用预训练模型得到的词向量表示)。
输入单词 $w_{it}$ 经过双向的RNN(GRU cell)得到每个 RNN cell 两个方向的隐状态,拼接作为该 time step $h_{it}$。然后使用 Attention 计算每个 $h_{it}$ 的重要性权重 $\alpha_{it}$ ,对权重softmax归一化之后,对 $h_{it}$ 加权求和得到句子的向量表示 $s_{i}$ 。
 (U 与 W 是线性映射矩阵,通过学习得到)
(U 与 W 是线性映射矩阵,通过学习得到)
到此第一层就结束了,根据输入的词向量得到了评论文本中每个句子的嵌入向量表示。
- Sentence Encoder + Attention
该层输入一段文本的各个句子向量(最多L个句子),输出该文本的嵌入向量表示。
输入的句子 $s_{i}$ 经过双向的RNN(GRU cell)得到每个 RNN cell 两个方向的隐状态,拼接得到每个句子的隐状态 $h_{i}$。使用 VGG-16 提取每个图像的特征向量 $m_{j}$,然后使用 $m_{j}$ 对 $h_{i}$ 作 Attention,得到每个 $h_{i}$ 对应的重要性权重 $\beta_{ji}$,最后对 $h_{i}$ 加权求和得到针对图 j 的该评论的文本表示 $d_{j}$。
 (V 与 W 是线性映射矩阵,通过学习得到)
(V 与 W 是线性映射矩阵,通过学习得到)
到此第二层就结束了,根据输入的句向量,利用一条评论中的多个图像对其进行 Attention,得到了针对每个图像生成的文本嵌入向量。(有几个图像就有几个文本表示 $d$ )
- Document Encoder + Attention
最后一层输入针对不同图像生成的多个文本 $d_{i}$ ,使用 Attention 计算得到对应的权重 $r_{i}$ ,然后进行加权求和得到最终的文本表示 $d$。最后是任务层,根据得到的文本向量 $d$ 作五分类任务,预测该评论的评分。

3 总结
VistaNet 的使用 Attention 的方式实现了文本与图像信息的融合,不会产生向量空间不一致问题,无形中还能学到文本与图像直接的关联信息,融合效果更佳。
读完此文,让我对信息融合的方式有了新的认识,启发很大,这种利用注意力机制进行信息融合的方式值得借鉴。